On this page
Starlet #28 Trench: Open source analytics infrastructure

This is the twenty-eighth issue of The Starlet List. If you want to prompt your open source project on star-history.com for free, please check out our announcement.
Trench is open source analytics infrastructure for tracking events, identifying users, and querying data in real time. It’s built on top of ClickHouse and Kafka for speed and scale, and it can be self-hosted easily with one Docker container. It's an alternative to tools like Segment, Amplitude, and Google Analytics.
Trench is MIT-licensed on GitHub. It launched recently and gained over 1,000 GitHub stars in less than a week 🚀

Problem - Postgres doesn't scale for tracking and querying millions of events at scale
As we’ve scaled our startup Frigade to millions of end users, our Postgres table we used for event tracking was quickly ballooning in cost and becoming a performance bottleneck. Many companies run into the same problem as us (e.g. Stripe, Heroku).
Engineers start by adding a basic events table to their relational database, which works at first, but breaks down as the user base scales. It's usually the biggest table in the database, the slowest one to query, and the longest one to back up. Postgres (or MySQL for that matter) simply isn't a good solution for tracking and querying events in real time at 1M+ end users scale.
Solution – fast, scalable, and affordable event tracking
We knew we wanted to move to technologies like Kafka and ClickHouse that are purpose-built for ingesting and querying thousands of events per second. When we looked for existing solutions, all the existing OSS projects we found were either bloated with unnecessary features, UIs and spaghetti code, or simply antiquated. So we built Trench.
When we migrated our tracking table from Postgres to Trench, we saw a 42% reduction in cost to serve on our primary Postgres cluster and eliminated all lag spikes from autoscaling under high traffic. We're happy with how Trench has solved event tracking for us, and now we’re excited to share that with other teams.
Core features of Trench
- Segment Specifications Compliant with the Segment tracking specifications
- Massive Throughput Can handle thousands of events per second on a single node
- Real-time Queries Query tracking data in real-time with read-after-write guarantees
- Webhooks Send data anywhere with throttled and batched webhooks
- Easy to Self-Host Single production-ready Docker image
- Scalability Easily plugs into cloud-hosted ClickHouse/Kafka solutions
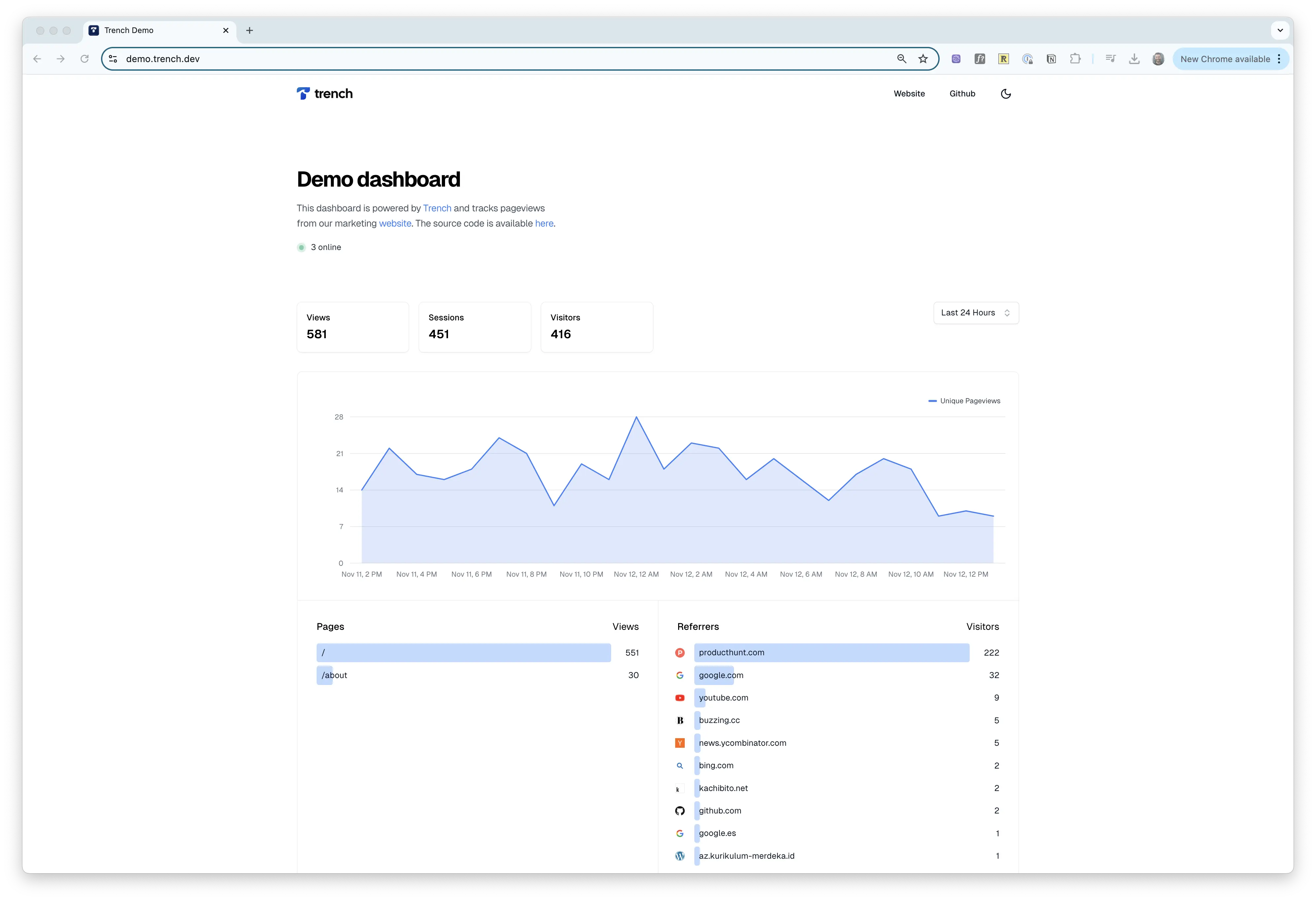
Demo
Check out our open source demo to see an open source Google Analytics dashboard powered by Trench that can be stood up in less than 10 minutes.
What can you build?
What else can you power with Trench? There are many use cases:
- Real-Time Monitoring and Alerting Monitor your services and get alerts through tracking custom events like errors, usage spikes, or specific user actions, and send that data anywhere with webhooks.
- Event Replay and Debugging Capture all user interactions in real time for event replay services.
- A/B Testing Platform Capture events from different users and groups in real time. Segment users by querying in real time and serve the right experiences to the right users.
- Product Analytics for SaaS Applications Embed Trench into your existing SaaS product to power user audit logs or tracking scripts on your end-users' websites
- Build a custom RAG AI model Easily query event data and give users answers in real time. LLMs are really good at writing SQL.
Learn more about Trench
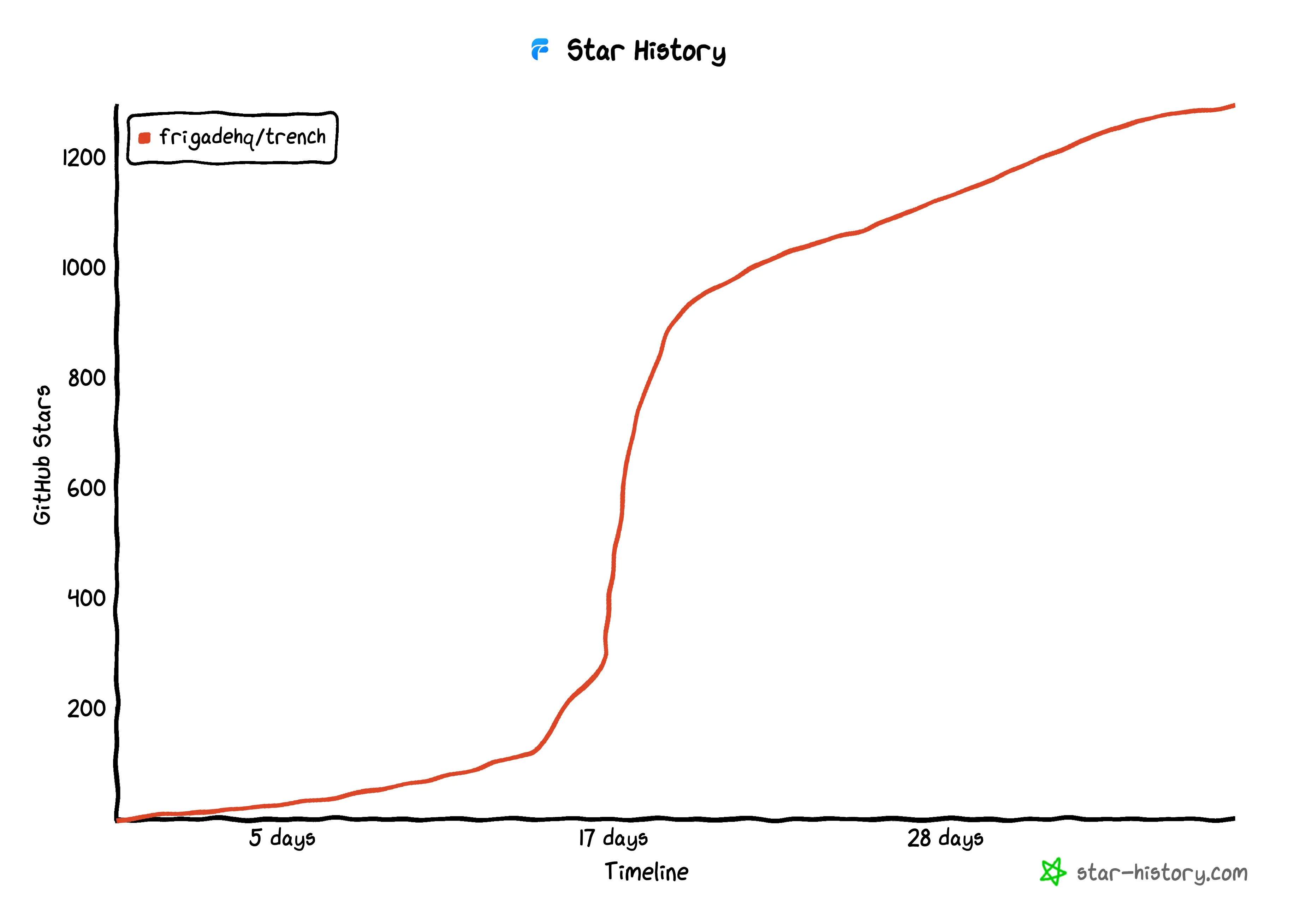
We hope you’ll find Trench useful if you’re facing or have ever experienced a similar problem with analytics at scale. Here are some links to get started:
