On this page
Star History Monthly Nov 2023 | Open-source Text To Speech Engines

Happy (almost) holidays! Can't believe we are already here: the last Star History Monthly of 2023.
A colleague of mine was making a tutorial series a while back and was looking at TTS apps to save her the hassle of recording and editing, which gave me the idea for this topic.
Text To Speech, or TTS, which means "from text to speech". It is a part of human-computer dialogue that enables machines to speak.
Actually, OpenAI started to roll out voice and image capabilities in ChatGPT this September, and you can basically speak to ChatGPT and have it talk back, or chat about images. But if you feel like having more freedom and control over your TTS program, here are a few open-source options to look at.
EmotiVoice
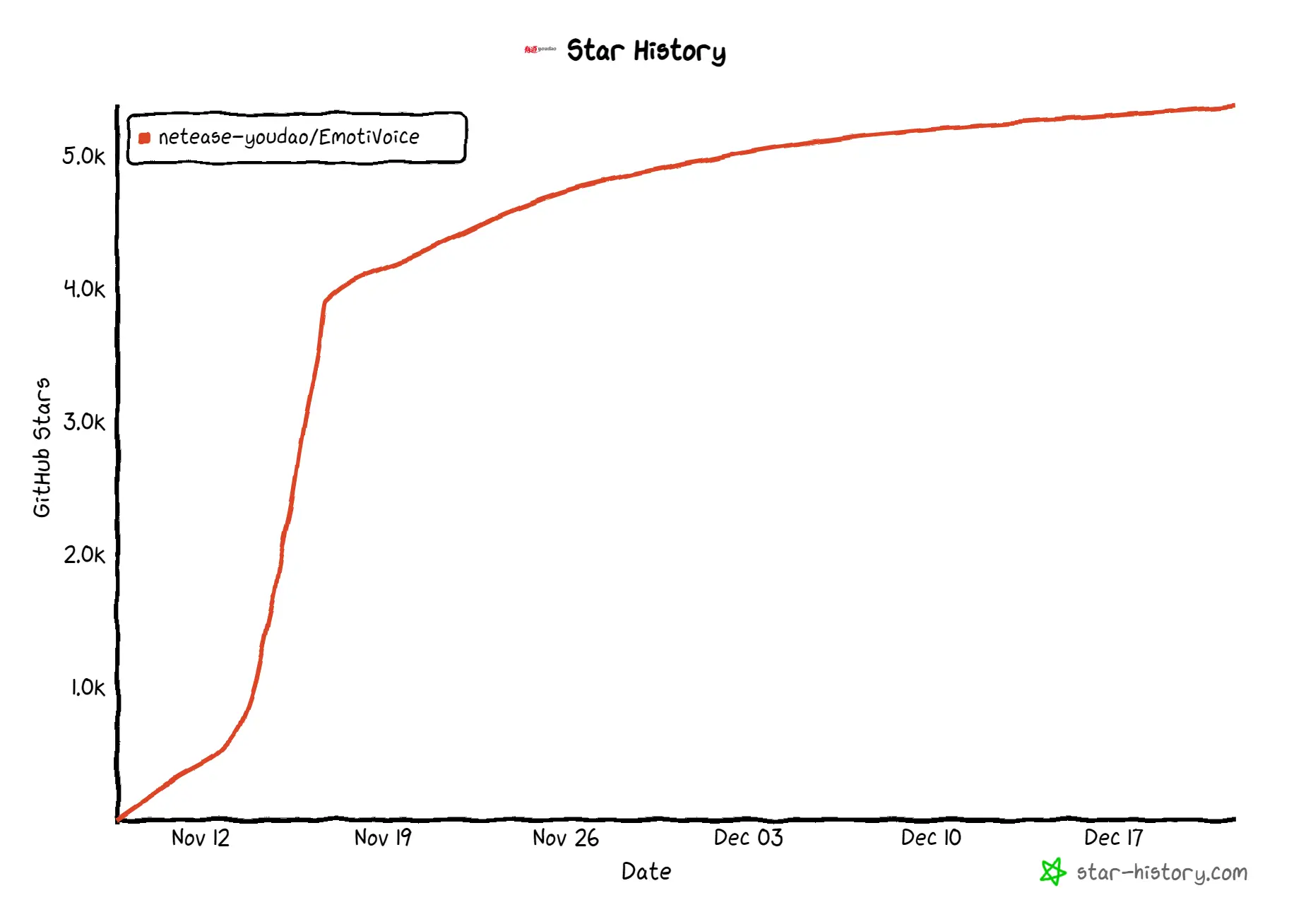
EmotiVoice is a multi-voice and prompt-controlled TTS engine, by the NetEase Youdao team. The project gained 4.2k stars within the first week of its launch.
EmotiVoice currently supports English and Chinese, with multiple voice and prompt controls. It offers over 2,000 different voices. The most prominent feature, as its name suggests, is emotional synthesis, which can create voices with various emotions such as happiness, excitement, sadness, anger, etc.
Coqui TTS 🐸
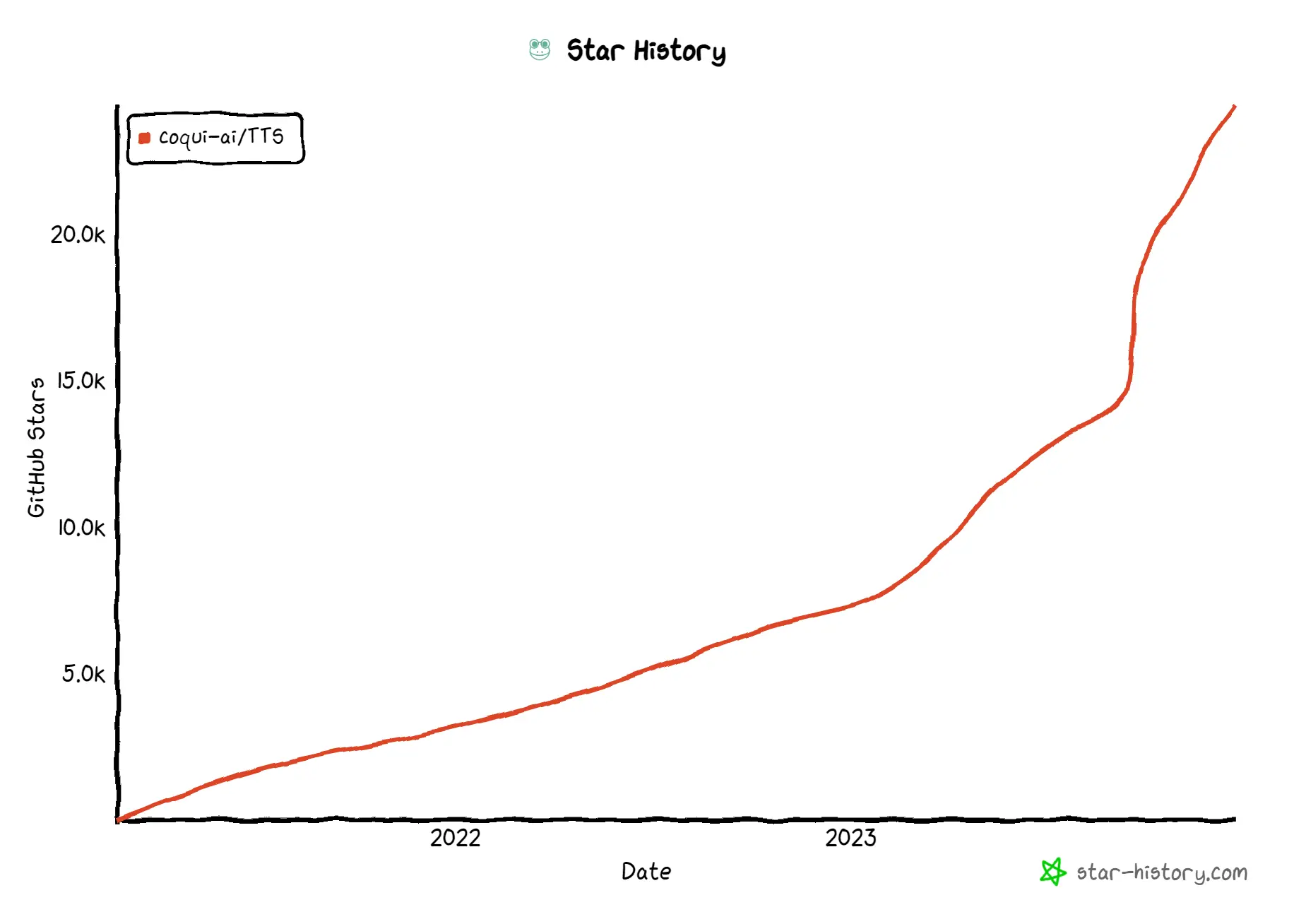
Coqui TTS is a TTS model that can clone voices in different languages in just 3 seconds. It enables cross-language voice cloning and multilingual speech generation so that you can quickly and easily create, cast, and direct AI voice actors. It's got:
- 🚀 Pretrained models in +1100 languages.
- 🛠️ Tools for training new models and fine-tuning existing models in any language.
- 📚 Utilities for dataset analysis and curation.
Coqui TTS is essentially a continuation of Mozilla's TTS: some time ago Mozilla stopped working on their TTS project, and Coqui.ai was founded by the founders of Mozilla’s machine learning group.
Note that it is licensed under MPL-2.0, which allows commercial use as well as modification of the code, but the copyright of the modified code belongs to the initiator of the software.
TorToiSe 🐢
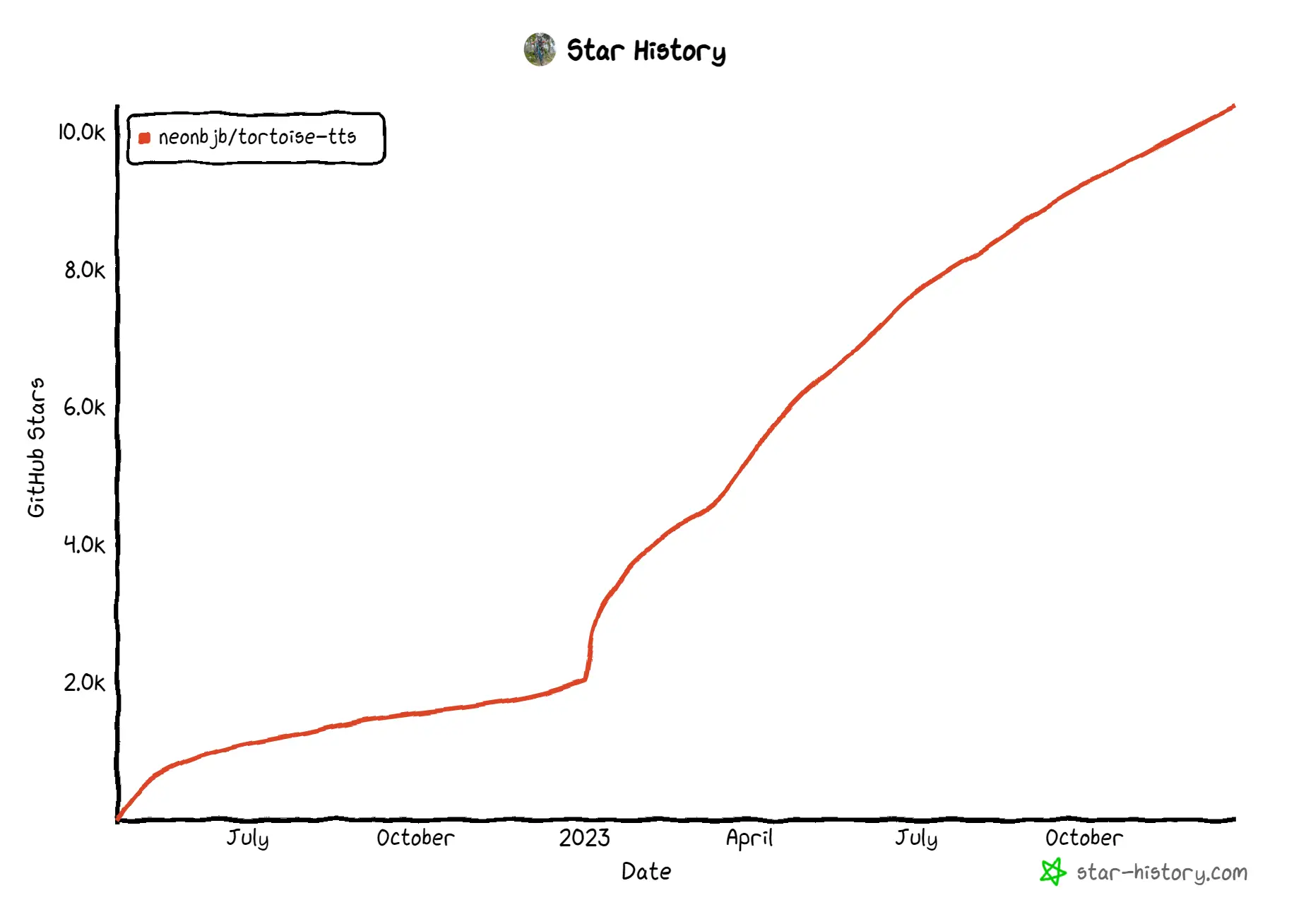
TorToiSe is a TTS program released in April 2022 (and got big in 2023). It has:
- Strong multi-voice capabilities.
- Highly realistic prosody and intonation.
The author of Tortoise was actually inspired by OpenAI's DALL-E model, released back in 2021. A while later, in 2022, the author joined OpenAI.
Tortoise is an advanced TTS system known for its exceptional voice cloning capabilities and expressiveness. Its architecture is similar to GPT (hard to imagine why), which transforms input text into discritized acoustic tokens. One notable drawback of Tortoise is it is slower, compared to other TTS models, due to the decoders it uses, which got the project its name.
Real-Time Voice Cloning
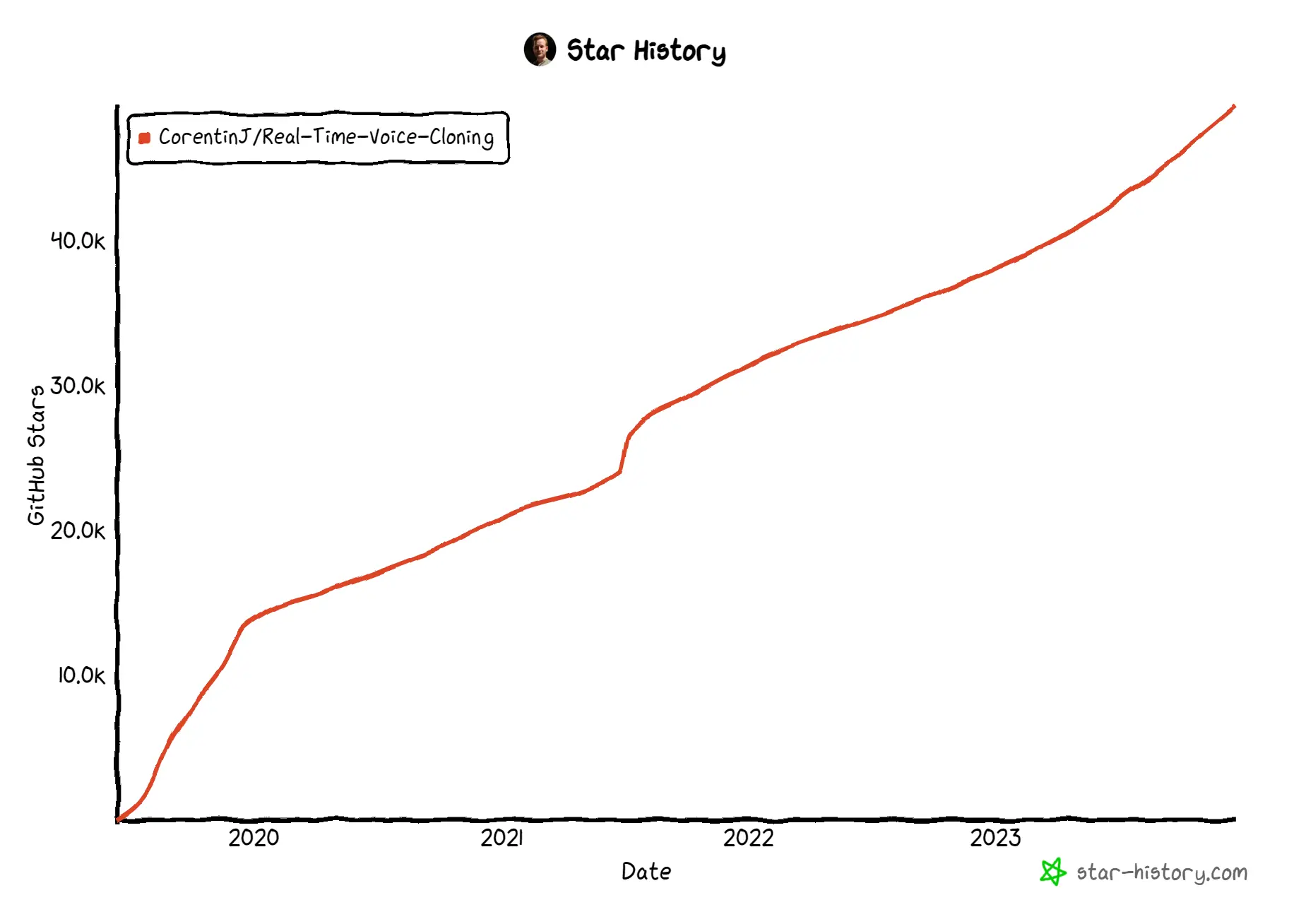
Real-Time Voice Cloning can generate arbitrary speech in real-time. It is an implementation of the paper "Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis" (SV2TTS, a deep learning framework) with a vocoder that works in real-time.
The project started way back in 2019, and the author (who currently works for an AI Voice Generator company), wrote that "just like everything else in Deep Learning, the Real-Time Voice Cloning repo is quickly getting old. Many other open-source repositories or SaaS apps (often paying) will give you a better audio quality than this repository will." Even so, the repo has not lost its momentum, and has been steadily gaining stargazers over the years.
VALL-E-X
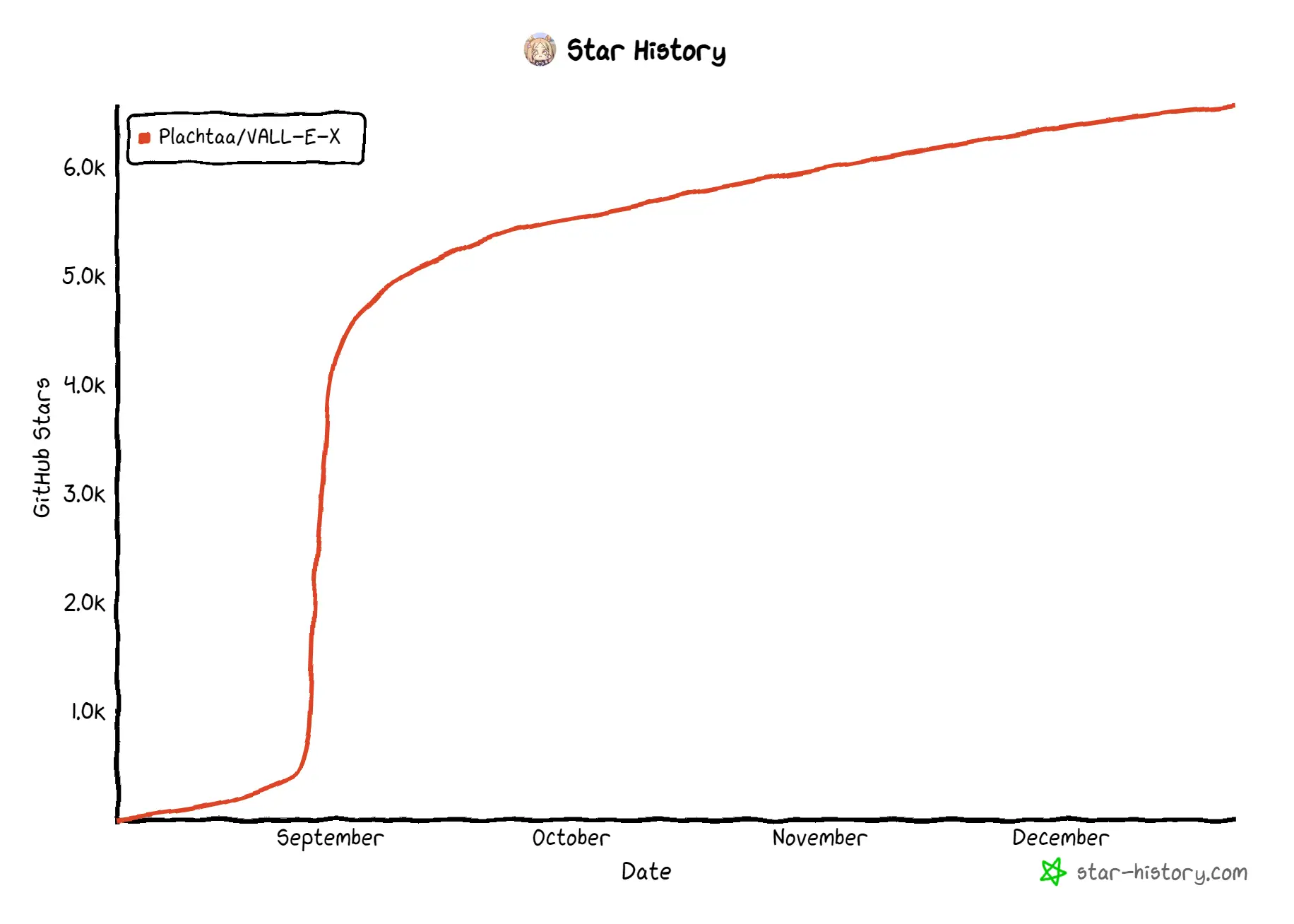
VALL-E-X is Microsoft's cross-lingual neural codec language model, which is an extension of its original VALL-E. Microsoft initially published the research paper, and a team at Nanyang Technological University reproduced the results and trained their own model.
VALL-E X can synthesize personalized speech in another language for a monolingual speaker. Thanks to its powerful in-context learning capabilities, VALL-E X does not require cross-lingual speech data of the same speakers for training and can perform various zero-shot cross-lingual speech generation tasks, such as cross-lingual text-to-speech synthesis and speech-to-speech translation.
Lastly
If you want more AI content, check out earlier editions of the star history open-source monthly:
