On this page
Star History Monthly May 2024 | Open Source AI Web Scrapers

Web scraping, in simpler words, is to scrape data and content from websites, the data is then saved in the form of XML, Excel, or SQL. On top of lead generation, competitor monitoring, market research, web scrapers can also be used to automate your data collection process.
With the help of AI web scraping tools, the limitations associated with manual or purely code-based scraping tools can be addressed: dynamic or unstructured websites can easily be handled, all without human intervention.
Here, we present a few open-source AI web scraping tools to choose from.
Reader
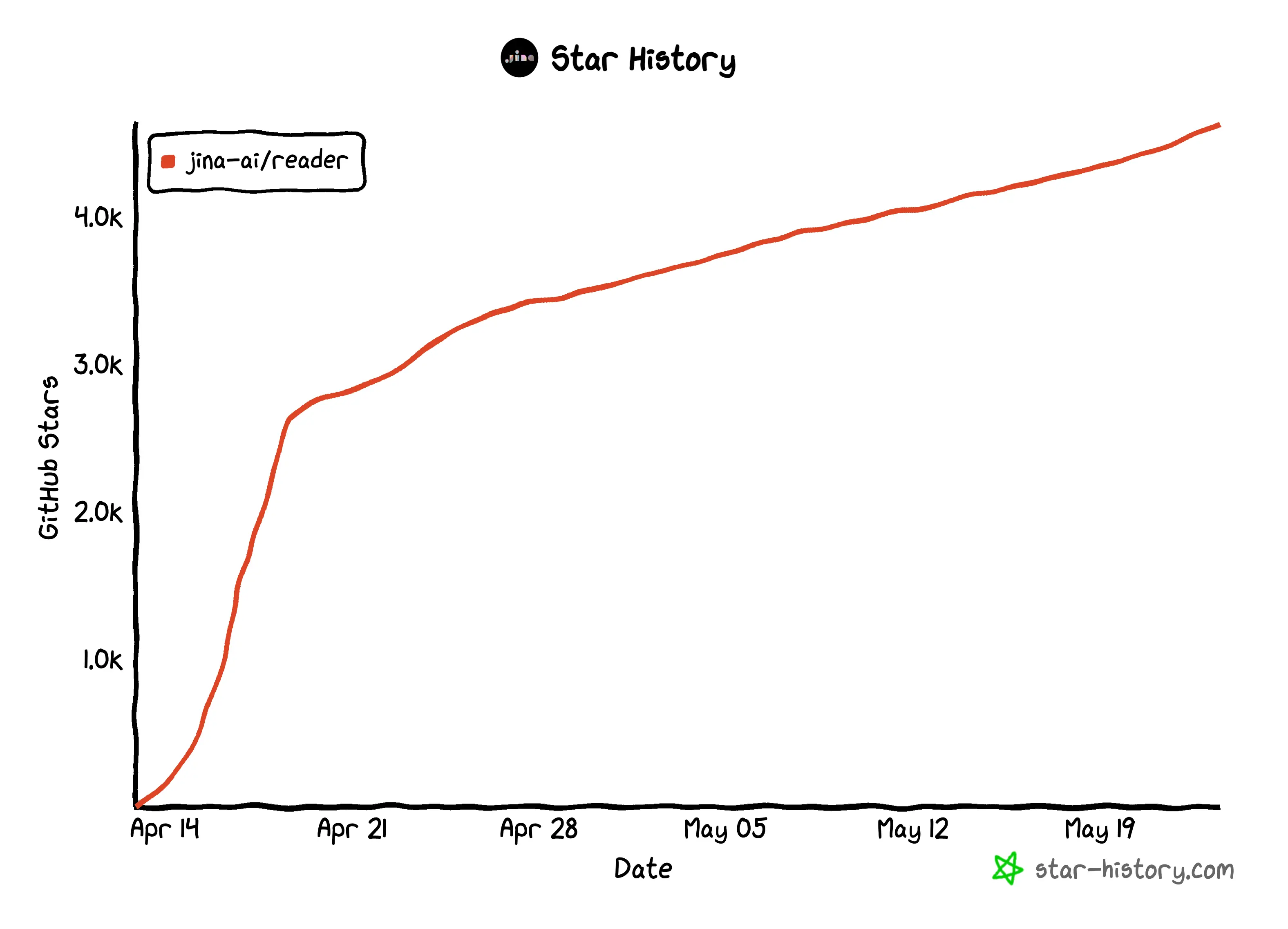
Reader is an offering by Jina AI. It can convert any URL to an LLM-friendly input when you append a simple https://r.jina.ai/, and you can get structured output for your agent and RAG systems at no cost.
Since its first release just this past month (April 15th, to be exact), they have served over 18M requests from the world, and the project itself has already gained 4.5K stargazers.
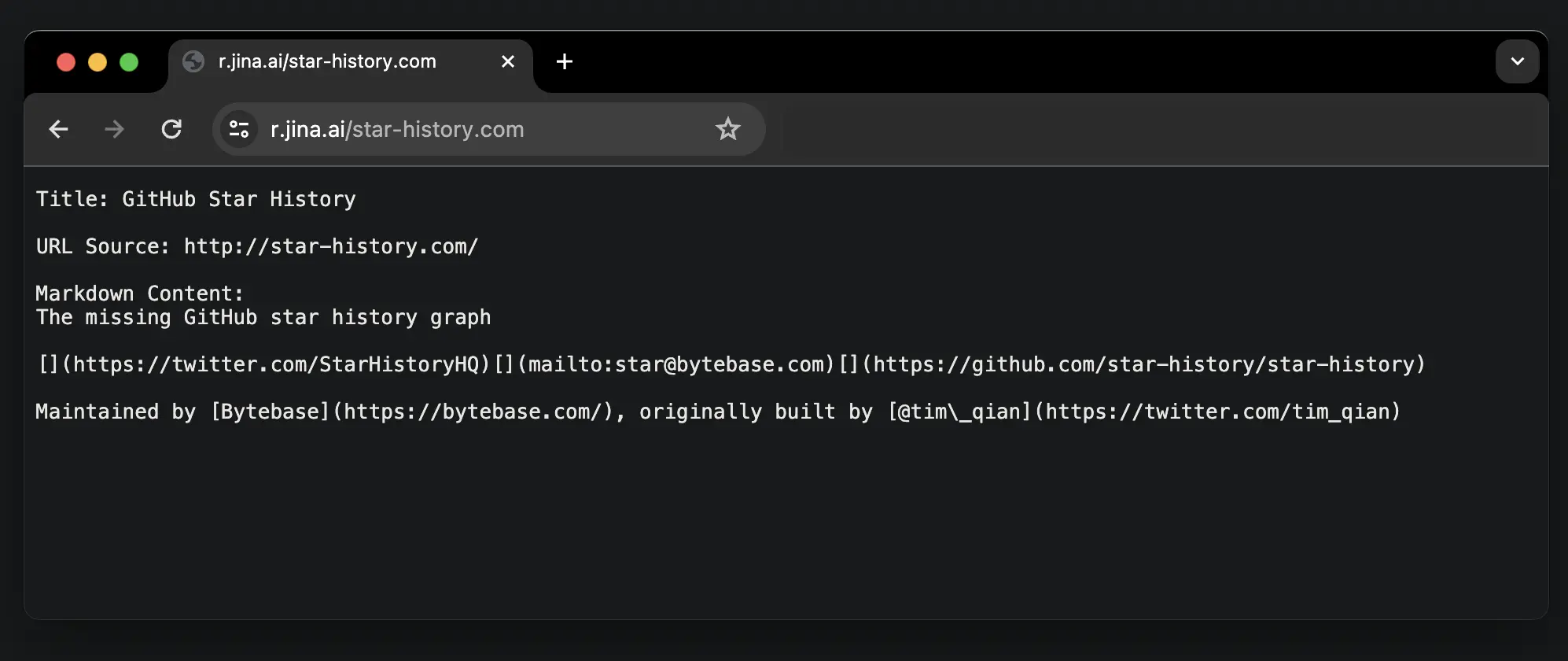
Aside from scraping any URL, Jina just released another feature where you can use https://s.jina.ai/YOUR_SEARCH_QUERY to search from the up-to-date knowledge on the Internet. The result includes a title, LLM-friendly markdown, and a URL that attributes the source.
Together, you can construct a comprehensive solution for LLMs, agents, and RAG systems.
LLM Scraper
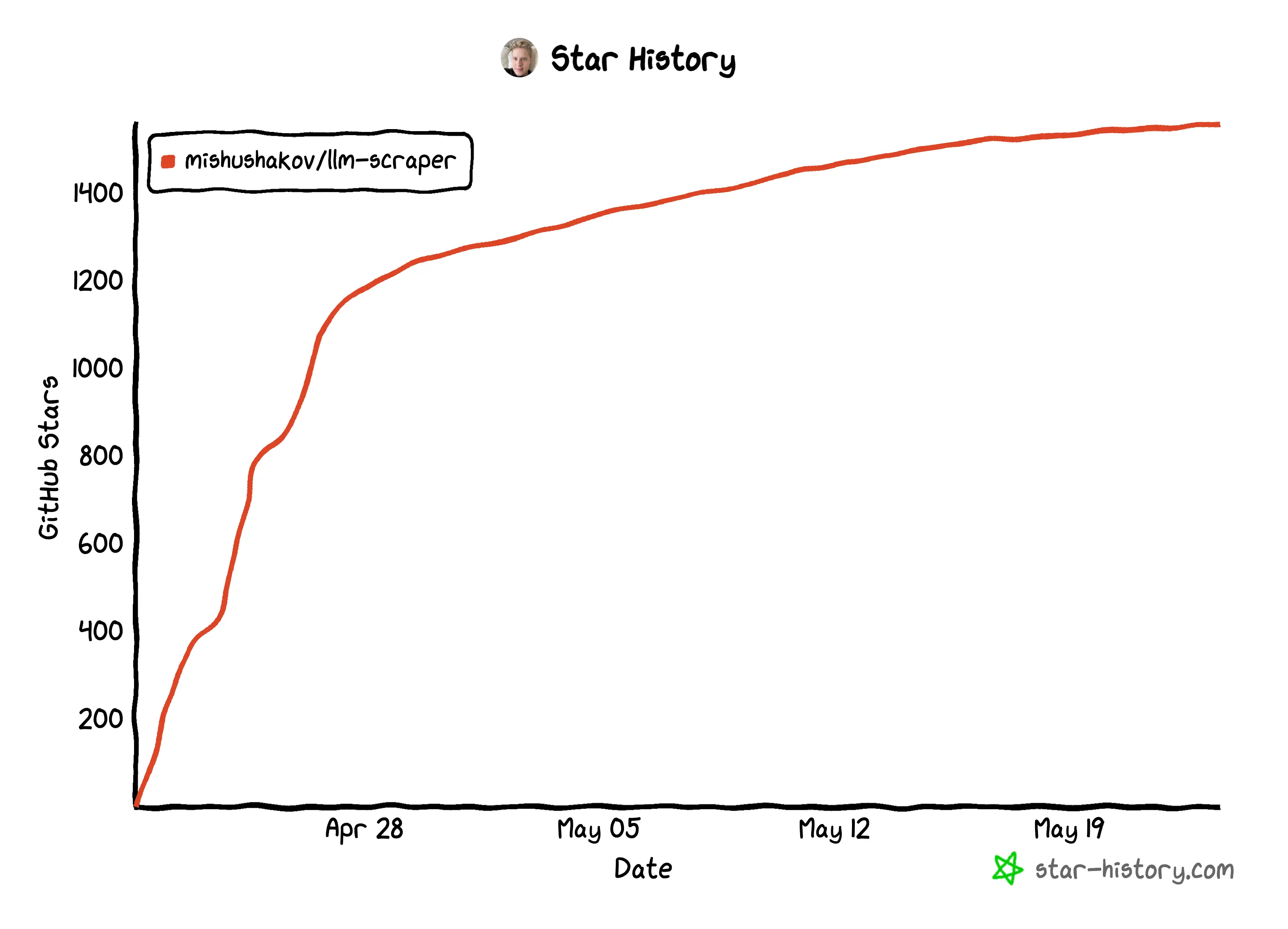
LLM Scraper is a TypeScript library that can convert any webpage into structured data using LLMs. Essentially, it uses function calling to convert pages to structured data.
Simliarly to Reader, it was open-sourced just last month. It currently supports Local (GGUF), OpenAI, Groq chat models. Apparently, the author is working on supporting local LLMs via llama.cpp to lower the cost of using LLMs for web scraping.
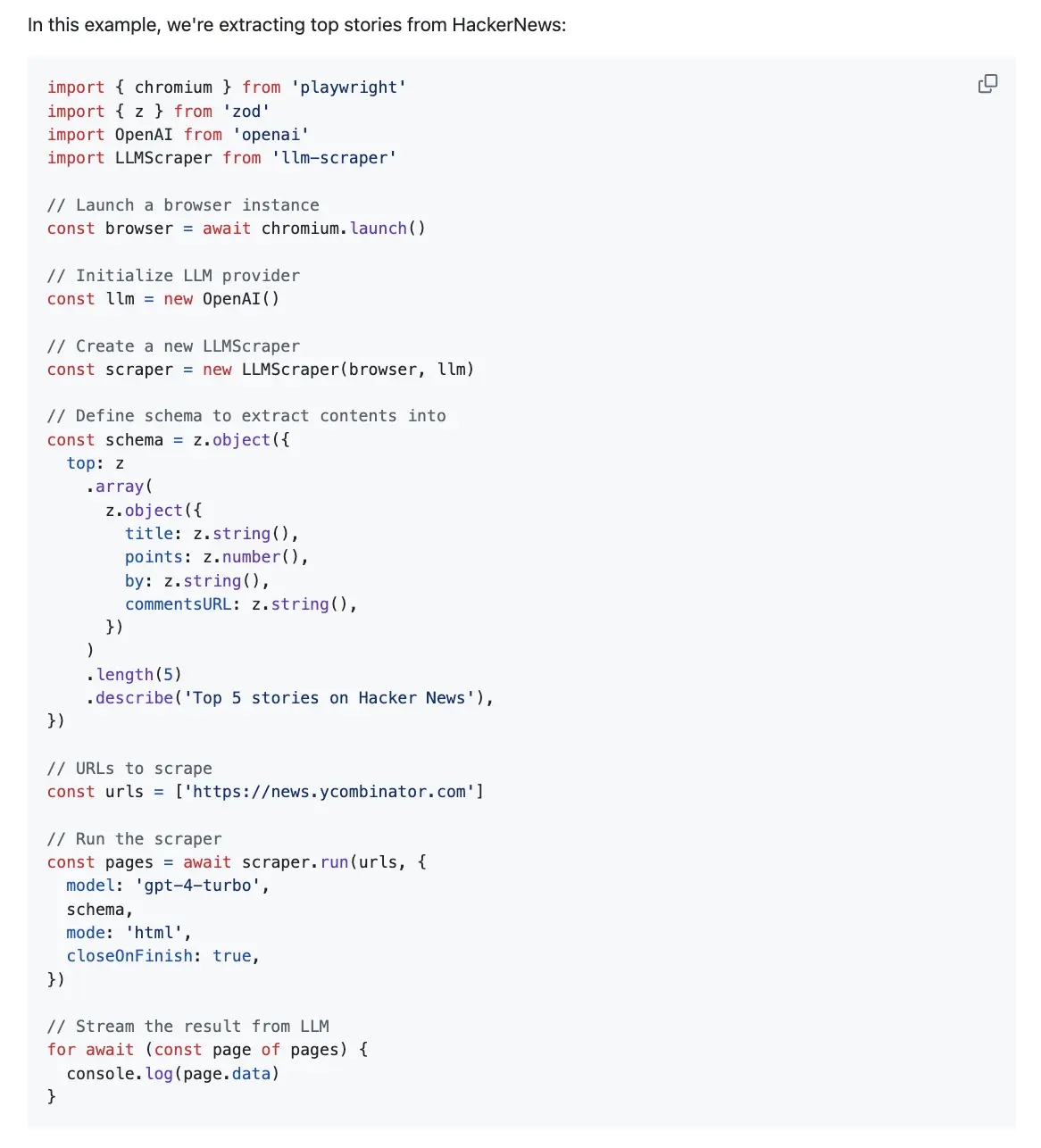
Firecrawl
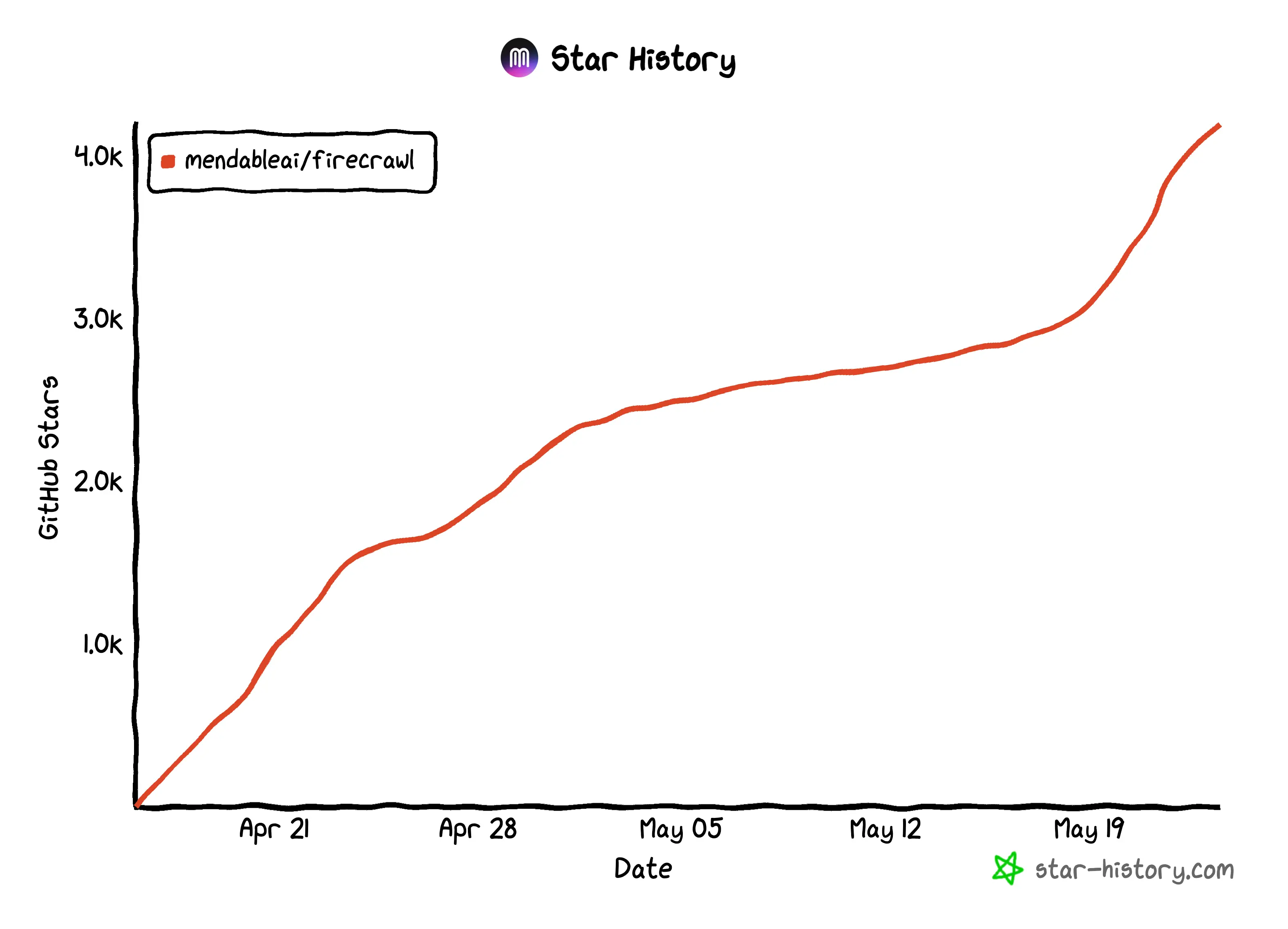
Firecrawl is an API service that can convert an URL into clean, well-formatted markdown. This format is great for LLM applications, offering a structured yet flexible way to represent web content.
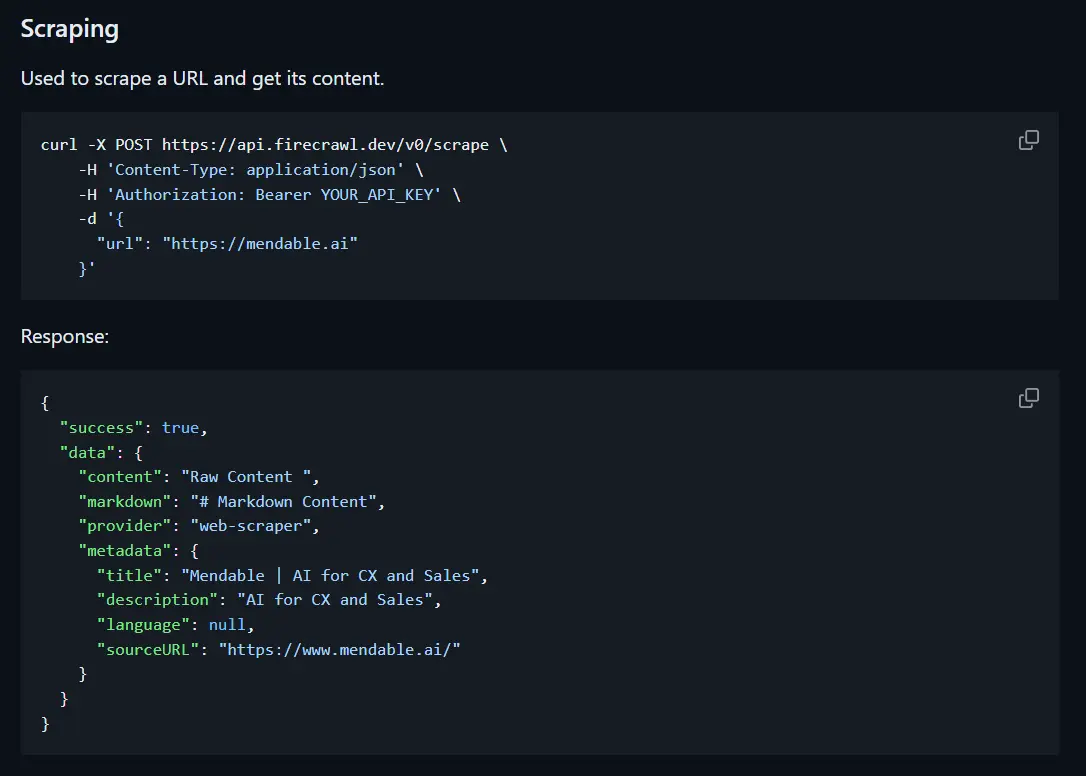
This tool is tailored for LLM engineers, data scientists, AI researchers, and developers looking to harness web data for training machine learning models, market research, content aggregation. It simplifies the data preparation process, allowing professionals to focus on insights and model development, and you can self-host it to your own taste.
ScrapeGraphAI
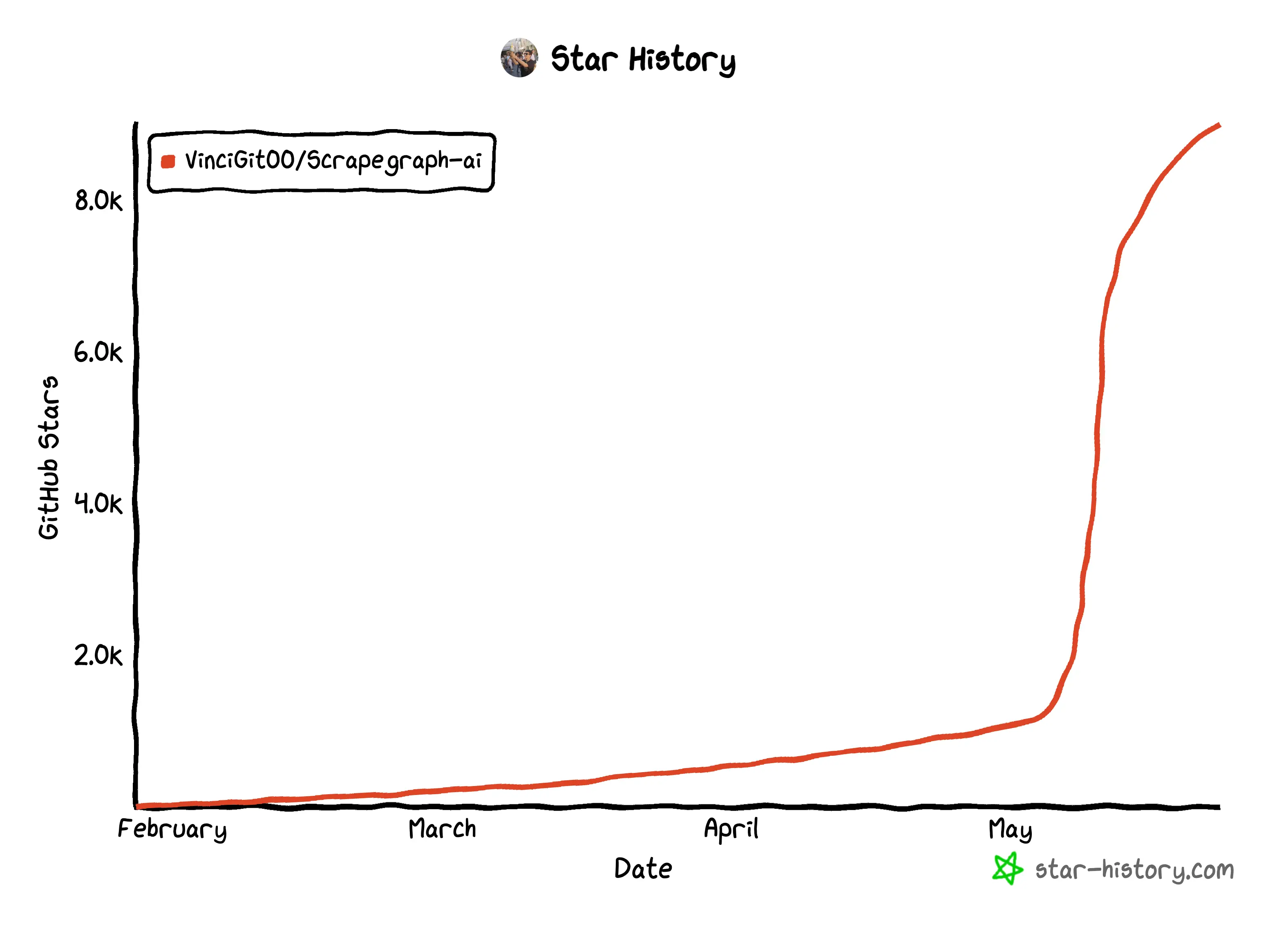
ScrapeGraphAI is a Python library that uses LLM and direct graph logic to create scraping pipelines for websites and local documents (XML, HTML, JSON, etc.). With ScrapeGraphAI, you get to specify exactly what sort of data you want to extract.

ScrapegraphAI leverages the power of LLMs, and can thus adapt to changes in website structures, reducing the need for constant developer intervention. This flexibility ensures that scrapers remain functional even when website layouts change.
The LLMs it currently supports include GPT, Gemini, Groq, Azure, Hugging Face, as well as local models.
LangChain
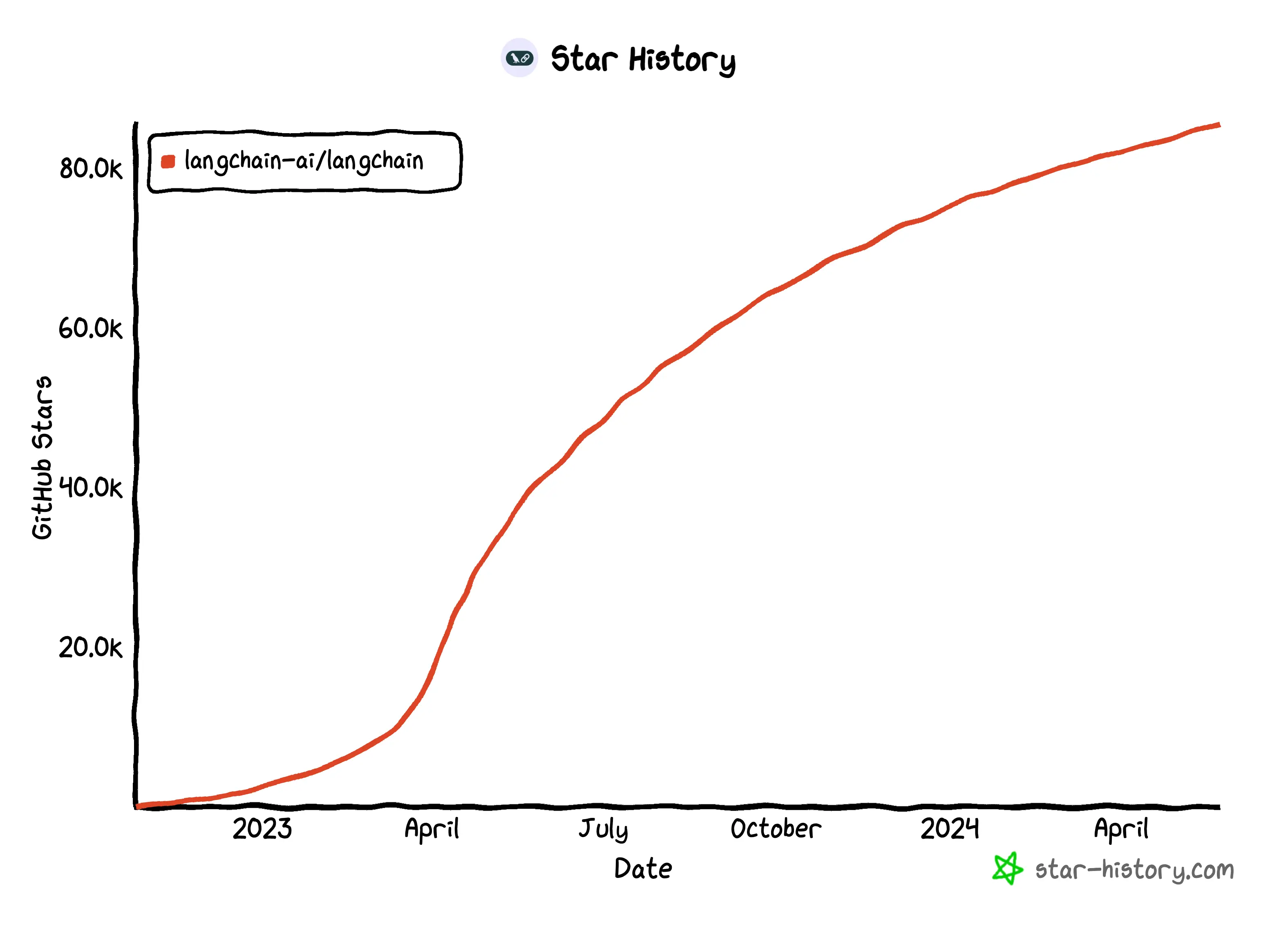
What is LangChain not capable of? Not web scraping.
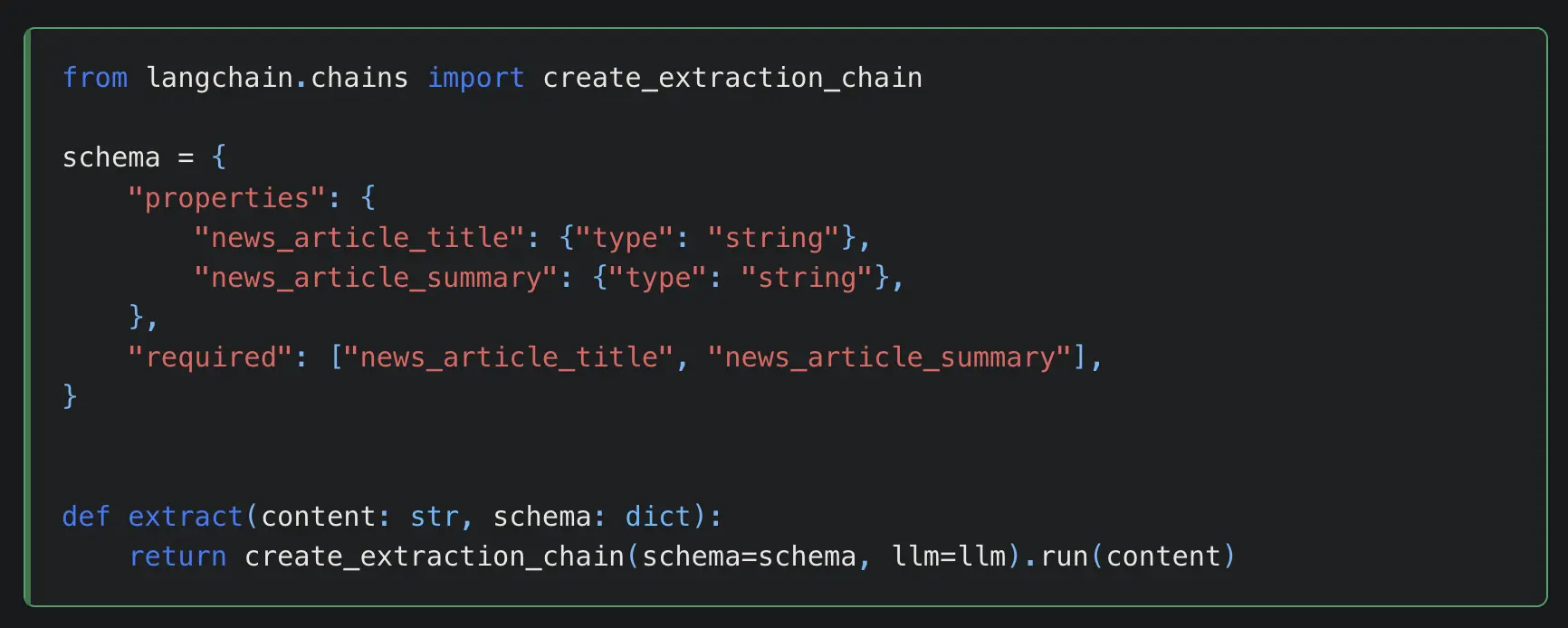
One of web scraping's biggest challenges is the changing nature of modern websites' layouts and content, which requires modifying scraping scripts to accommodate the changes, and LangChain also utilizes function (e.g., OpenAI) with an extraction chain, so that you don't have to change your code constantly when websites change.
If you are doing research and want to scrape only news article's name and summary from The Wall Street Journal website, it's got you covered.
To Sum Up
Of course, there is no one-size-fits-all web scraper. Do you prefer old-school traditional web scrapers or LLM-empowered ones?
📧 Subscribe to our weekly newsletter here.
