On this page
Starlet #26 thepi.pe: Intelligent Document Scraping with Vision-Language Models

This is the twenty-sixth issue of The Starlet List. If you want to prompt your open source project on star-history.com for free, please check out our announcement.
![]()
thepi.pe is an open-source package for intelligent document scraping at scale using vision-language models (VLMs). It works for dozens of file types. Unlike traditional scrapers, thepi.pe has no problems with poorly scanned PDFs, highly complex visuals, and irregularly formatted tables. It's designed to work with state-of-the-art models like GPT-4o and it integrates easily with LLM APIs, vector databases, and RAG frameworks.
How it works
thepi.pe uses a combination of computer vision models and carefully crafted heuristics to extract clean content from various sources. It processes this content for downstream use with language models or vision transformers.
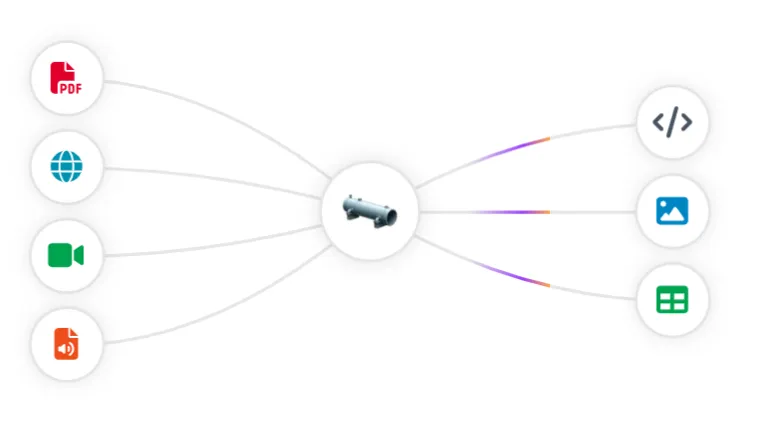
The output from thepi.pe is a list of chunks containing all content within the source document. These chunks can be easily converted to a prompt format compatible with any LLM or multimodal model using thepipe.core.chunks_to_messages.
Key Features
- Multimodal Extraction: Extract clean markdown, tables, and images from documents or webpages.
- Structured Data Extraction: Extract structured data as JSON or CSV from any document or webpage.
- VLM-based Document Analysis: Utilizes AI for filetype detection, layout analysis, and data extraction.
- Wide Format Support: Works with PDFs, word docs, powerpoints, webpages, videos, images, and more.
- LLM Integration: Seamlessly interfaces with any language model (GPT4, Claude, LLaMa) and vector databases like LlamaIndex.
Getting Started
Install thepi.pe:
pip install thepipe-api
Here's a quick example of how to use thepi.pe with the hosted API:
from thepipe.scraper import scrape_file
from thepipe.core import chunks_to_messages
from openai import OpenAI
# Scrape markdown, tables, visuals
chunks = scrape_file(filepath="paper.pdf", ai_extraction=True)
# Call LLM with clean, comprehensive data
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=chunks_to_messages(chunks),
)
Supported File Types
thepi.pe supports a wide range of file types, including:
- Webpages (URLs)
- PDFs
- Word Documents
- PowerPoint Presentations
- Videos and Audio files
- Jupyter Notebooks
- Spreadsheets
- Images
And it's easily extensible to support any custom file type of your choice.
Learn More and Contribute
If you're excited about intelligent document processing and want to try thepi.pe for yourself, visit our GitHub repository!
- GitHub: https://github.com/emcf/thepipe
- Website: https://thepi.pe/
Join us in shaping the future of intelligent document processing! Thank you to the organizers of Star History's Starlet program for this opportunity to present thepi.pe to the best minds in the industry.
