On this page
Starlet #2 DLTA-AI - Data Labeling, Tracking and Annotation with AI

This is the second issue of The Starlet List. If you want to prompt your open source project on star-history.com for free, please check out our announcement.
Problem
The annotation process is a critical component of computer vision tasks and can greatly impact the accuracy of the resulting model. However, manual annotation is a time-consuming and resource-intensive task, often requiring significant human labor. Therefore, developing an Auto Annotation tool for computer vision tasks is of utmost importance, as it has the potential to save significant time and resources while also improving the quality of the annotations and the resulting models.
Solution
The solution is to develop an automated annotation tool that can accurately and efficiently label objects in images and videos for tasks such as instance segmentation and object tracking. The tool is called DLTA-AI (Deep Learning Tool for Annotation - Artificial Intelligence) and it has the following features:
Input modes
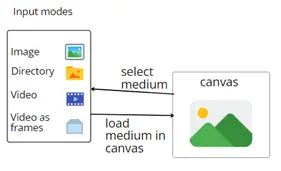
DLTA-AI supports four input modes to provide flexibility to the user depending on the application. These are: Image: load an image in the canvas to work with.
Directory mode: load a directory of images to work with. This is useful when working with a dataset containing different images that need to be annotated together. Parallel processing is used to enhance the speed of the annotation process when applying inference using deep learning model.
Video mode: load a video to work with. A video bar is presented below the video to allow the user to navigate through the video either by time or by frame number. The video is not loaded entirely in memory, but only the corresponding frame is loaded when needed. This allows the tool to handle large video sizes with long durations efficiently without worrying about insufficient memory.
Video as frames: convert a chosen video into frames to work with in directory mode. The user can specify the start and end time or frame number of the video, as well as the sampling rate or time of that interval.
Segmentation models
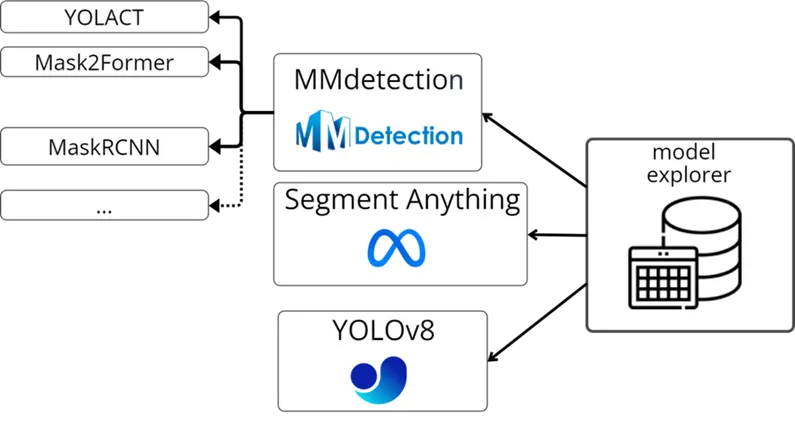
DLTA-AI supports a variety of segmentation models to provide accurate and consistent annotations for objects in images and videos. These models include:
Mmdetection: a library that contains many state-of-the-art models for instance segmentation, object detection, panoptic segmentation, and more.
Segment anything (SAM) : a model that can segment any object in any image or video, even including objects and image types that it had not encountered during training. It uses foundation models that can perform zero-shot and few-shot learning for new datasets and tasks using prompting techniques.
YOLOv8 family: a family of models that offer relatively fast results with reasonable accuracy.
The user can explore and download these models using the model explorer feature that allows for easy exploration, download, and automatic path file configuration in the tool. The user can also select any model from a model selection menu in the toolba0.
DLTA-AI also provides tuning controls for the user to adjust the segmentation parameters, such as:
- Confidence threshold: filter out detections with low confidence scores.
- IOU threshold: perform non-maximum suppression on detections with overlapping bounding boxes using intersection over union metric.
- Select classes: choose which classes to include or exclude from the segmentation results.
Additionally, DLTA-AI allows merging multiple segmentation models together to benefit from their combined strengths and overcome their limitations. The tool runs all the chosen models in combination, then compares and merges their results based on their bounding box similarity and confidence scores².
Tracking algorithms
DLTA-AI supports multiple tracking algorithms to provide reliable and relevant annotations for objects in videos. The user can select any tracking algorithm from a tracking selection menu in the toolbar. The user can also customize the tracking process using various tracking options, such as:
- Track for certain number of frames or full video tracking: choose whether to track a specific number of frames or the entire video.
- Track selected objects: choose which objects to track from the segmentation results.
- Stop button with dynamic result saving: pause the tracking process at any time and save the results up to that point.
DLTA-AI also incorporates interpolation methods to fill in the gaps when the detection models fail to segment certain objects or when the objects are stationary. The user can choose between linear interpolation or interpolation with segment anything model, as well as specify the key frames to interpolate between.
Export
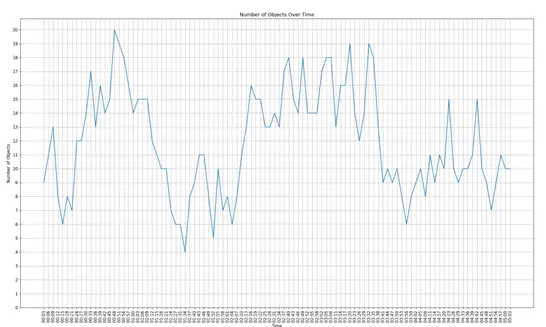
DLTA-AI allows the user to export the annotations to standard formats, or any custom format such as plot, dashboard or even a report.
In the figure above, we opened a video showing a street, sampled it by taking a frame every 3 seconds, annotated it and exported the results as this traffic graph.
Star Growth
DLTA-AI is still very young, but looks like it's been growing steadily since its open-source (April, 2023, which was only a few months ago!). Good luck, folks!
