On this page
Star History Monthly August 2024 | RAG Frameworks

Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. It helps overcome limitations such as knowledge cutoff dates and reduces the risk of hallucinations in LLM outputs.
RAG works by retrieving relevant information from a knowledge base and using it to augment the LLM’s input, allowing the model to generate more accurate, up-to-date, and contextually relevant responses.
For this edition, we'll present some well-featured open-source RAG frameworks that represent the cutting edge of RAG technology and are worth investigating.
Haystack
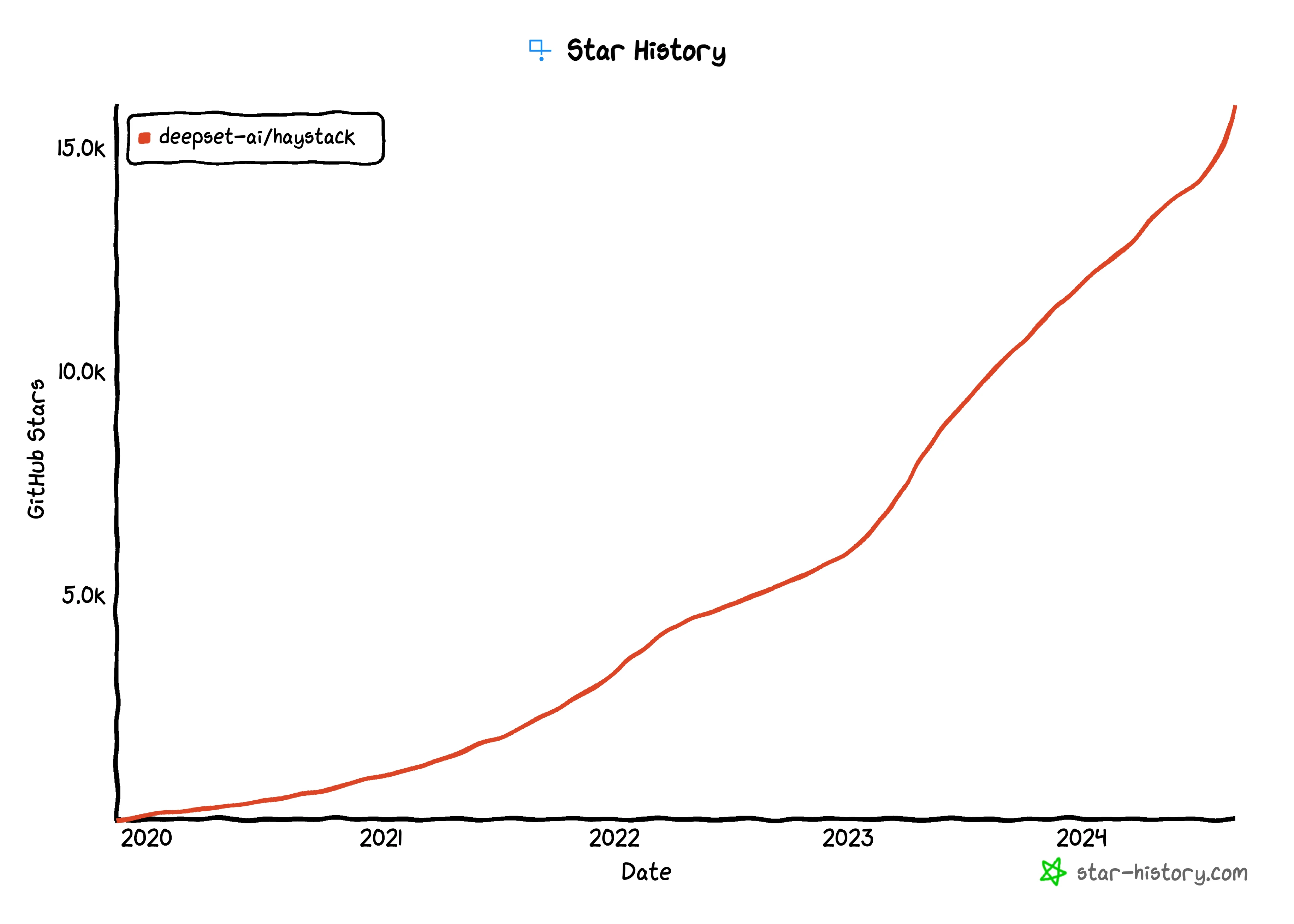
Haystack is an end-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more. Whether you want to perform RAG, document search, question answering or answer generation, Haystack can orchestrate state-of-the-art embedding models and LLMs into pipelines to build end-to-end NLP applications and solve your use case.

Haystack supports multiple installation methods including Docker images. You can simply get Haystack via pip.
RAGFlow
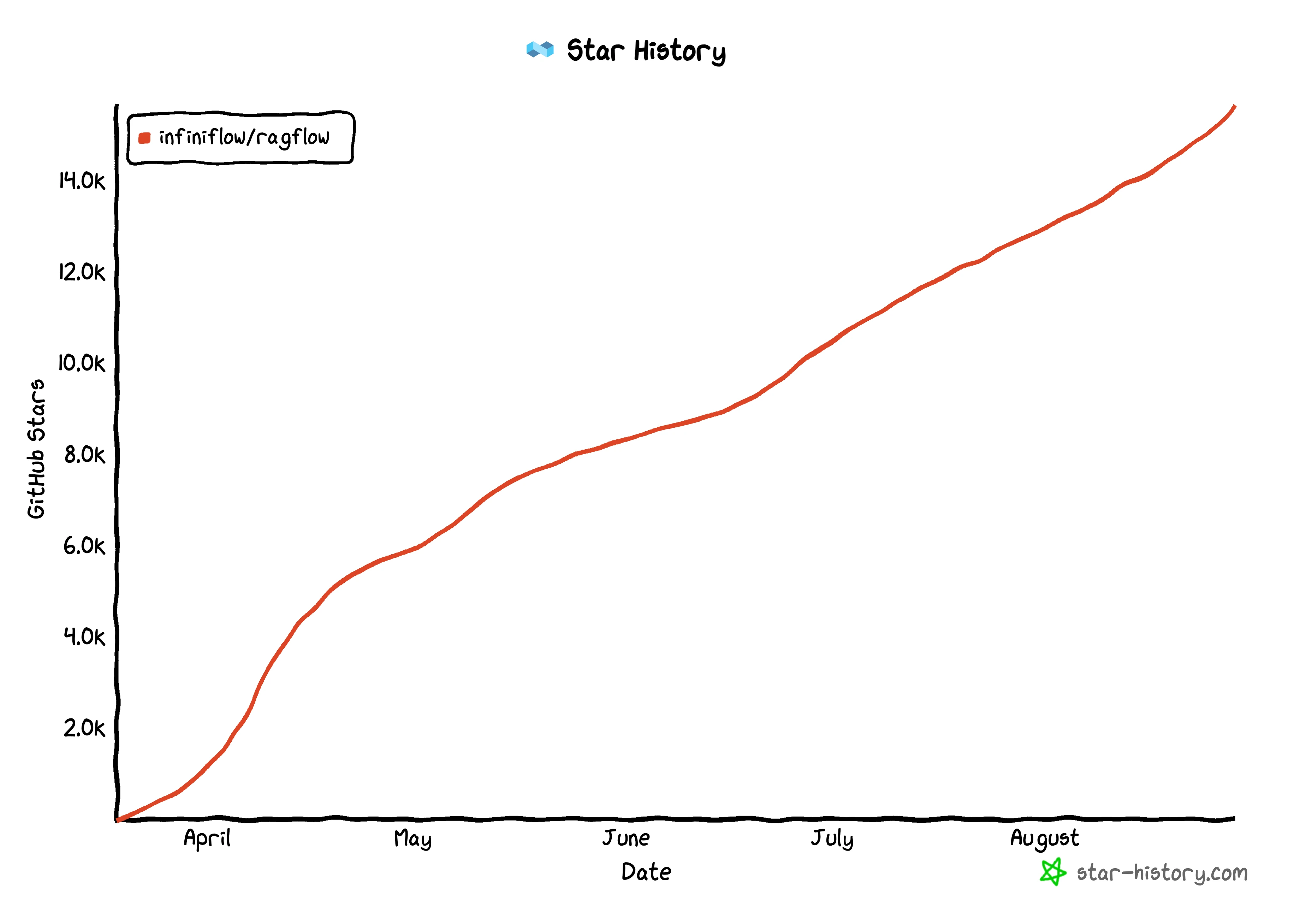
RAGFlow offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data. It features "Quality in, quality out", template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and automated and effortless RAG workflow.
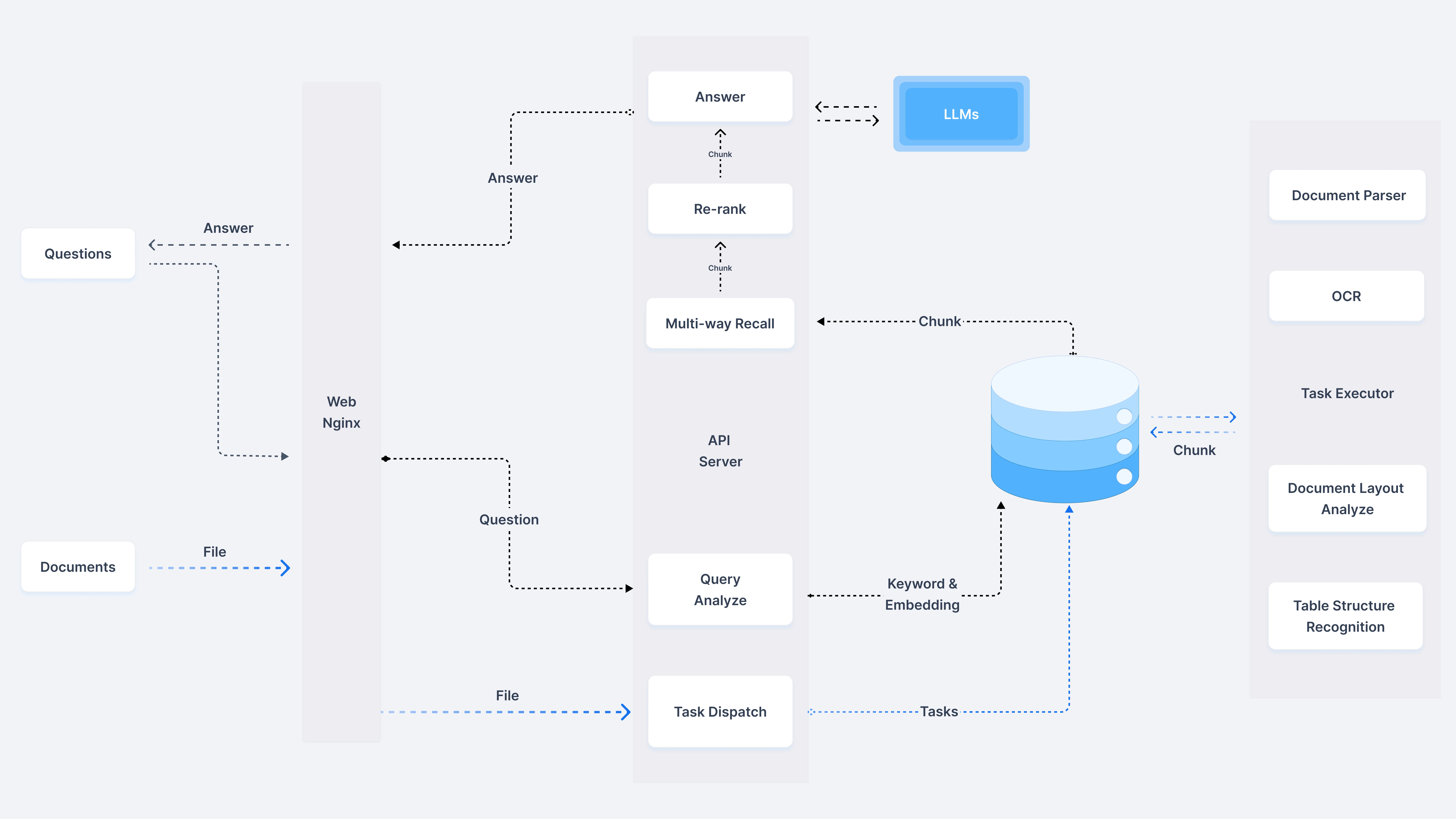
With CPU >= 4 cores, RAM >= 16 GB, Disk >= 50 GB, Docker >= 24.0.0 & Docker Compose >= v2.26.1, you can clone the repo in GitHub, build the pre-built Docker images and start up the server.
STORM
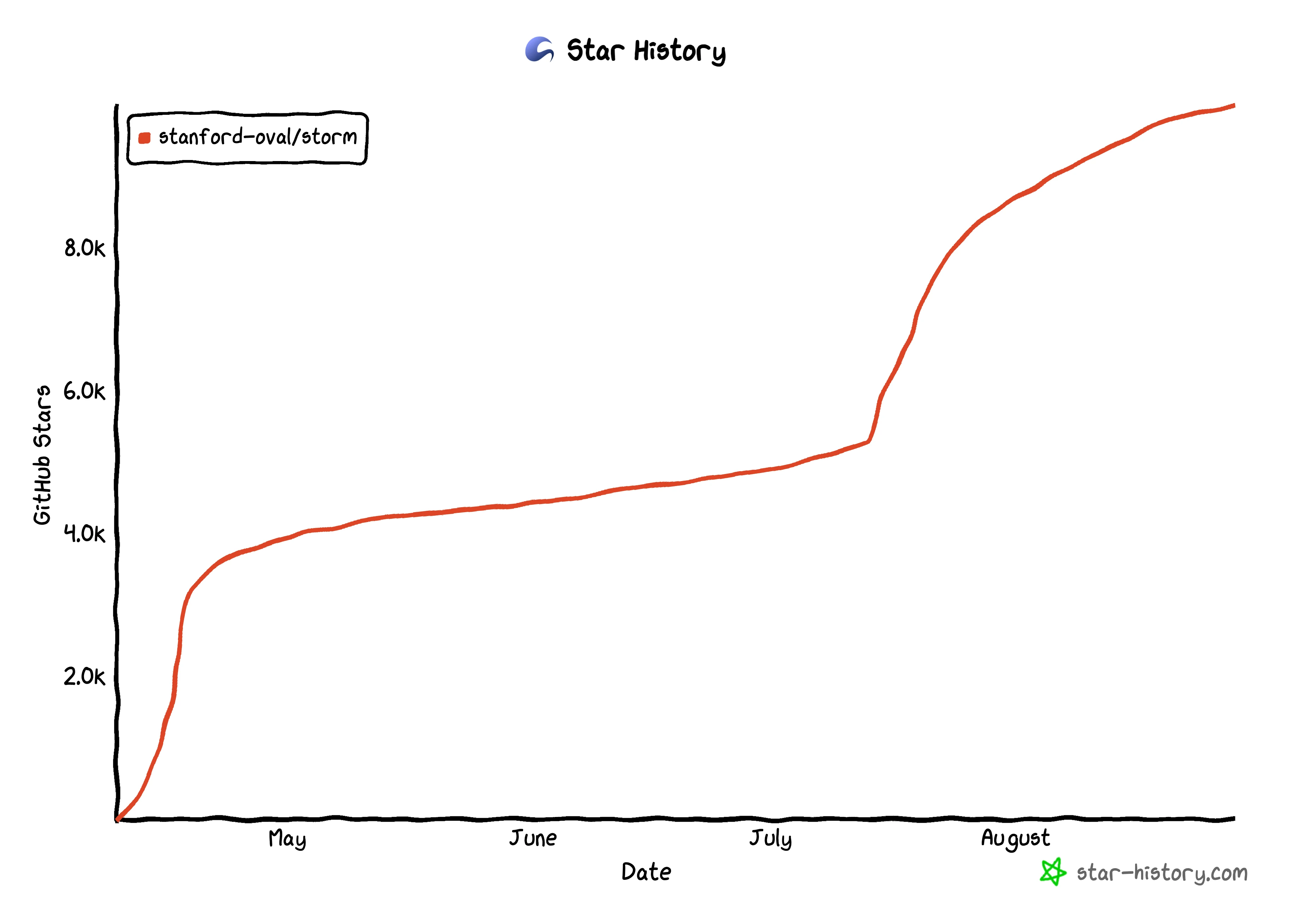
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. It breaks down generating long articles with citations into two steps: Pre-writing stage and Writing stage, and identifies the core of automating the research process as automatically coming up with good questions to ask. To improve the depth and breadth of the questions, STORM adopts two strategies: Perspective-Guided Question Asking and Simulated Conversation. Based on the separation of the two stages, STORM is implemented in a highly modular way using dspy.
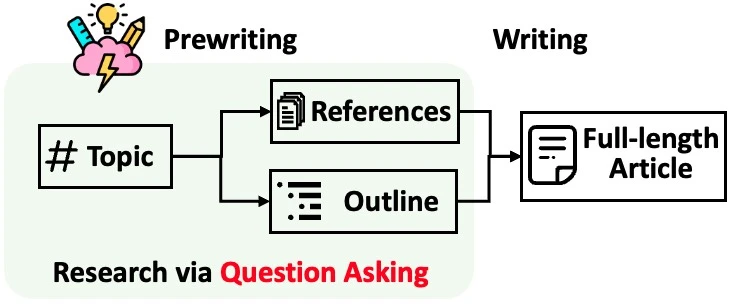
To install the knowledge storm library, you could either use pip or install the source code on GitHub which allows you to modify the behavior of STORM engine directly. The STORM knowledge curation engine is defined as a simple Python STORMWikiRunner class. As STORM is working in the information curation layer, you need to set up the information retrieval module and language model module to create a STORMWikiRunner instance.
FlashRAG
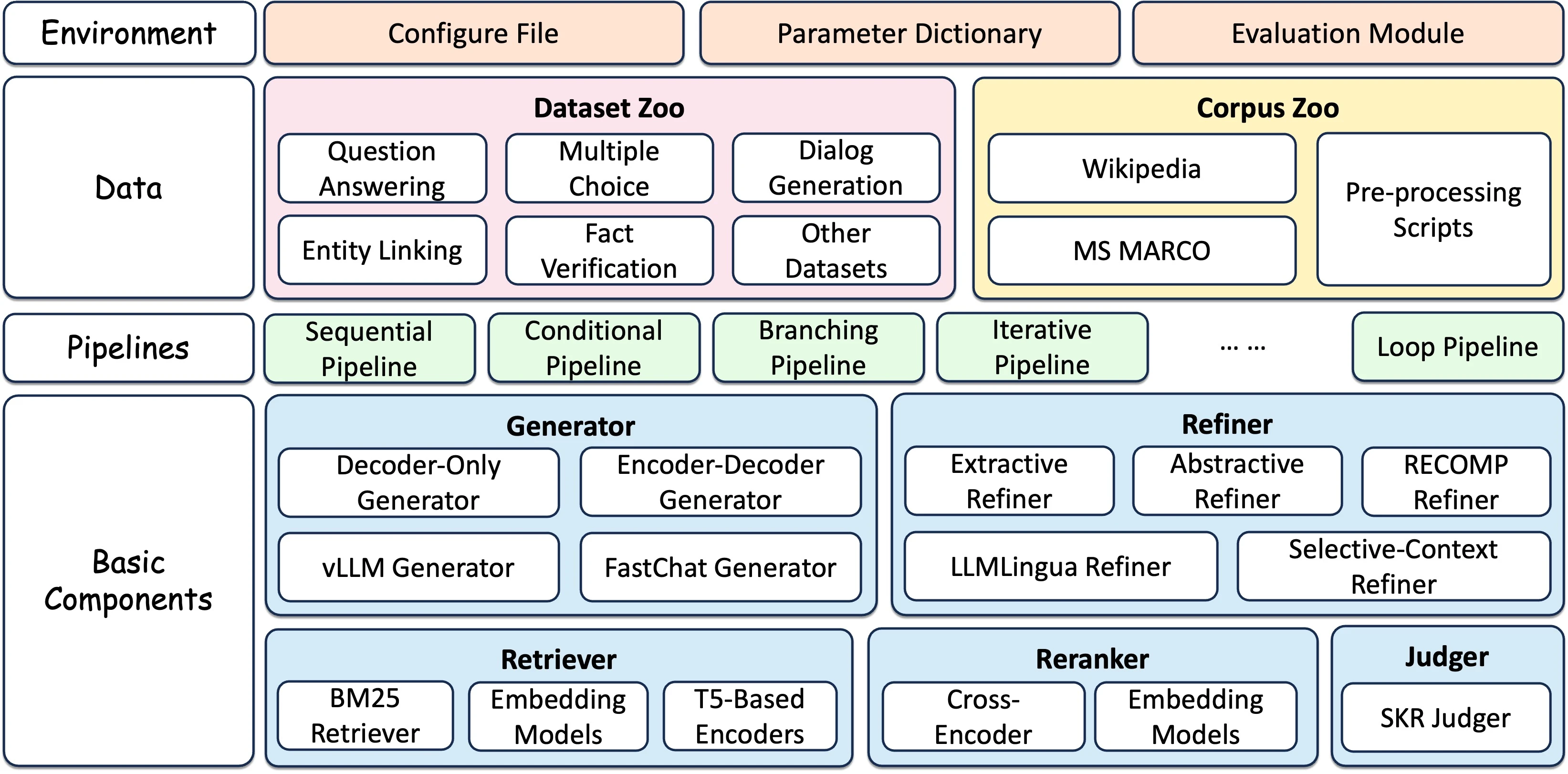
FlashRAG is a Python toolkit for the reproduction and development of RAG research including 32 pre-processed benchmark RAG datasets and 14 state-of-the-art RAG algorithms. With FlashRAG and provided resources, you can reproduce existing SOTA works in the RAG domain or implement your custom RAG processes and components.
FlashRAG features Extensive and Customizable Framework, Comprehensive Benchmark Datasets, Pre-implemented Advanced RAG Algorithms, Efficient Preprocessing Stage, and Optimized Execution. It's still under development and more good functions are to be uncovered.
To get started with FlashRAG, simply clone it from Github and install (requires Python 3.9+).
Canopy
Canopy is an open-source RAG framework and context engine built on top of the Pinecone vector database enabling you to quickly and easily experiment with and build applications using RAG. Just start chatting with your documents or text data with a few simple commands.
Canopy takes on the heavy lifting for building RAG applications: from chunking and embedding your text data to chat history management, query optimization, context retrieval (including prompt engineering), and augmented generation. It provides a configurable built-in server so you can effortlessly deploy a RAG-powered chat application to your existing chat UI or interface. Or you can build your own, custom RAG application using the Canopy library. It lets you evaluate your RAG workflow with a CLI based chat tool as well. With a simple command in the Canopy CLI you can interactively chat with your text data and compare RAG vs. non-RAG workflows side-by-side.
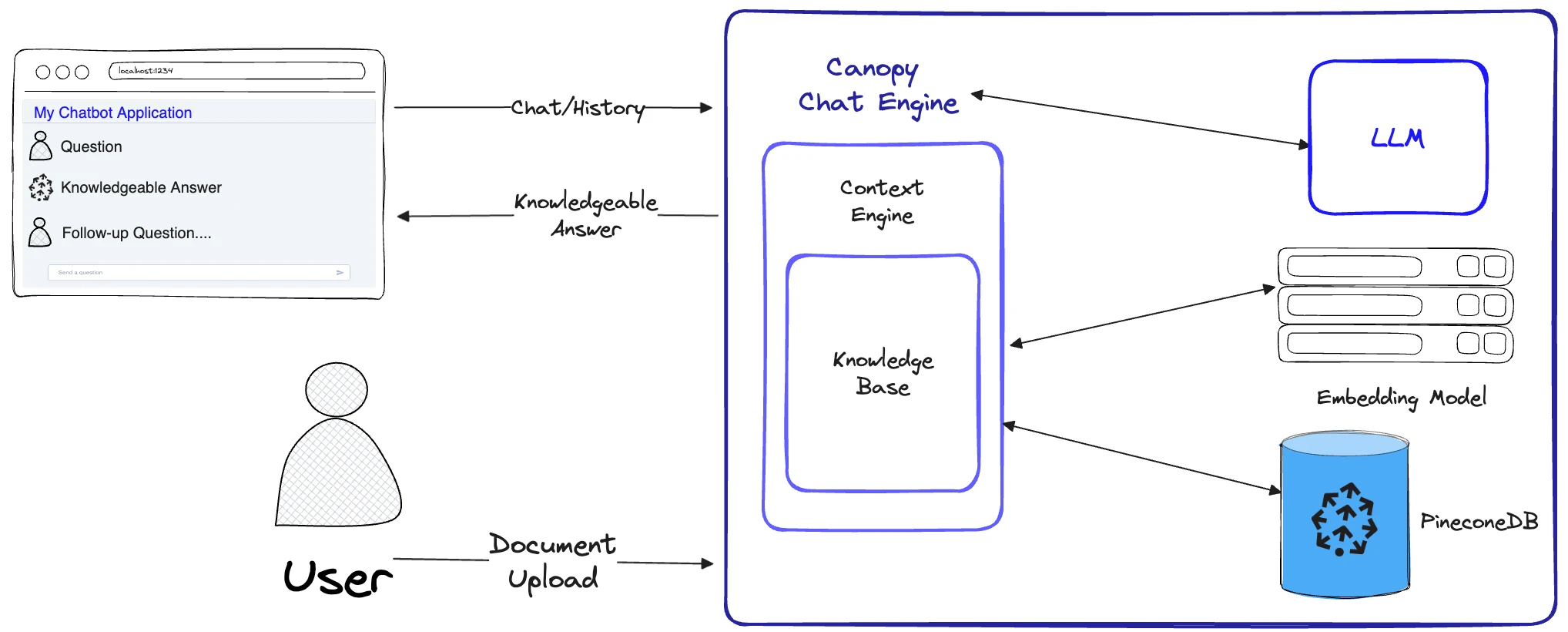
To get Canopy, simply set up environments via pip and download the package according to tutorial docs. You may have to set up a virtual environment.
Lastly
By carefully evaluating and experimenting with different frameworks, you may eventually find the RAG solution that best fits your needs. Let's expect these frameworks to evolve and new ones to emerge in the future.
📧 Subscribe to our weekly newsletter here.
